AI & ML
10 articles

FlashAttention Explained: Why Modern LLMs Run Faster
FlashAttention computes exact attention without ever materializing the N×N matrix in GPU memory, treating attention as a memory-movement problem instead of a FLOP-counting one. The payoff: up to 3× faster GPT-2 training, 15% off the BERT-large MLPerf record, and the long context windows modern LLMs rely on.

DPO Explained: Aligning LLMs Without RLHF Complexity
Direct Preference Optimization (DPO) proves the RLHF objective has a closed-form solution, letting you express the reward in terms of the policy itself. The result: a single classification loss replaces the entire reward-model-plus-PPO pipeline, matching or beating RLHF on sentiment, summarization, and dialogue.

DeepSeek-R1 Explained: RL for Reasoning Models
DeepSeek-R1 showed that large language models can learn to reason through reinforcement learning alone — no supervised chain-of-thought data required. This review walks through the pure-RL R1-Zero result, the four-stage pipeline behind the production model, the benchmark numbers against OpenAI o1, and the honest list of what didn't work.

Stable Diffusion Paper Explained: Latent Diffusion Models
Latent Diffusion Models move diffusion out of pixel space: an autoencoder compresses images into a small latent grid, and the U-Net generates that instead, cutting compute by an order of magnitude. A cross-attention layer makes it a general conditional generator. This is the architecture behind Stable Diffusion.

What Is a Vector Database? (and When You Actually Need One)
A clear, jargon-light explanation of what a vector database is and how ANN indexing actually works — then the honest part most articles skip: when pgvector in the Postgres you already run is enough, and when scale, latency, or real-time indexing genuinely justify a dedicated engine like Pinecone, Qdrant, or Milvus.

LoRA Explained: Low-Rank Adaptation for Cheap Fine-Tuning
LoRA freezes a pretrained model's weights and trains a tiny pair of low-rank matrices to represent the update instead. On GPT-3 175B it trains ~10,000x fewer parameters and matches full fine-tuning quality, and because the update merges back into the weights it adds zero inference latency.
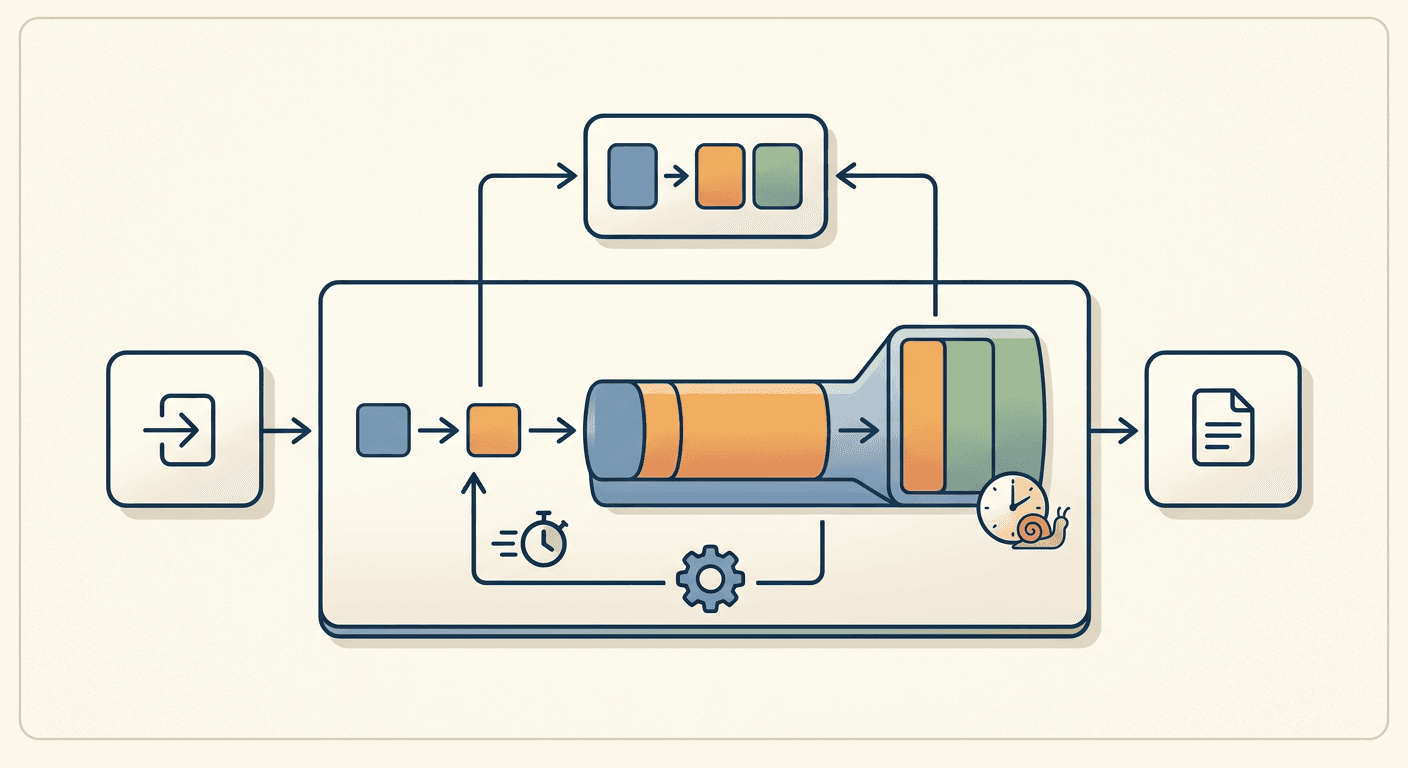
KV Cache Explained: Why LLM Inference Slows Down
LLM generation slows down on long contexts because of one data structure: the KV cache. It grows linearly with every token and must be re-read in full on each decode step, making decode memory-bandwidth bound. Here is the formula, the real numbers, and how GQA, MLA, PagedAttention, and prefix caching fight back.

How LoRA Fine-Tuning Works (and When to Use It)
LoRA freezes a model's pretrained weights and trains a tiny low-rank update instead, cutting trainable parameters by ~10,000x and GPU memory by ~3x. This explainer covers how the mechanism works, what QLoRA and the variants add, and an honest, research-backed framework for when LoRA wins and when full fine-tuning still beats it.

What Is RAG? Retrieval-Augmented Generation Explained
Retrieval-Augmented Generation (RAG) grounds an LLM's answers in information it pulls from an external knowledge source at query time, instead of relying on frozen training data. Here's what RAG is, how the indexing and retrieval pipelines actually work, and when to choose it over fine-tuning or long-context.

How Speculative Decoding Speeds Up LLM Inference
Speculative decoding makes LLM inference 2-3x faster by letting a small draft model guess ahead and a large model verify the guesses in one parallel pass. A rejection-sampling step keeps the output mathematically identical to the slow path. Here's how it works, why it's lossless, and where it stops helping.