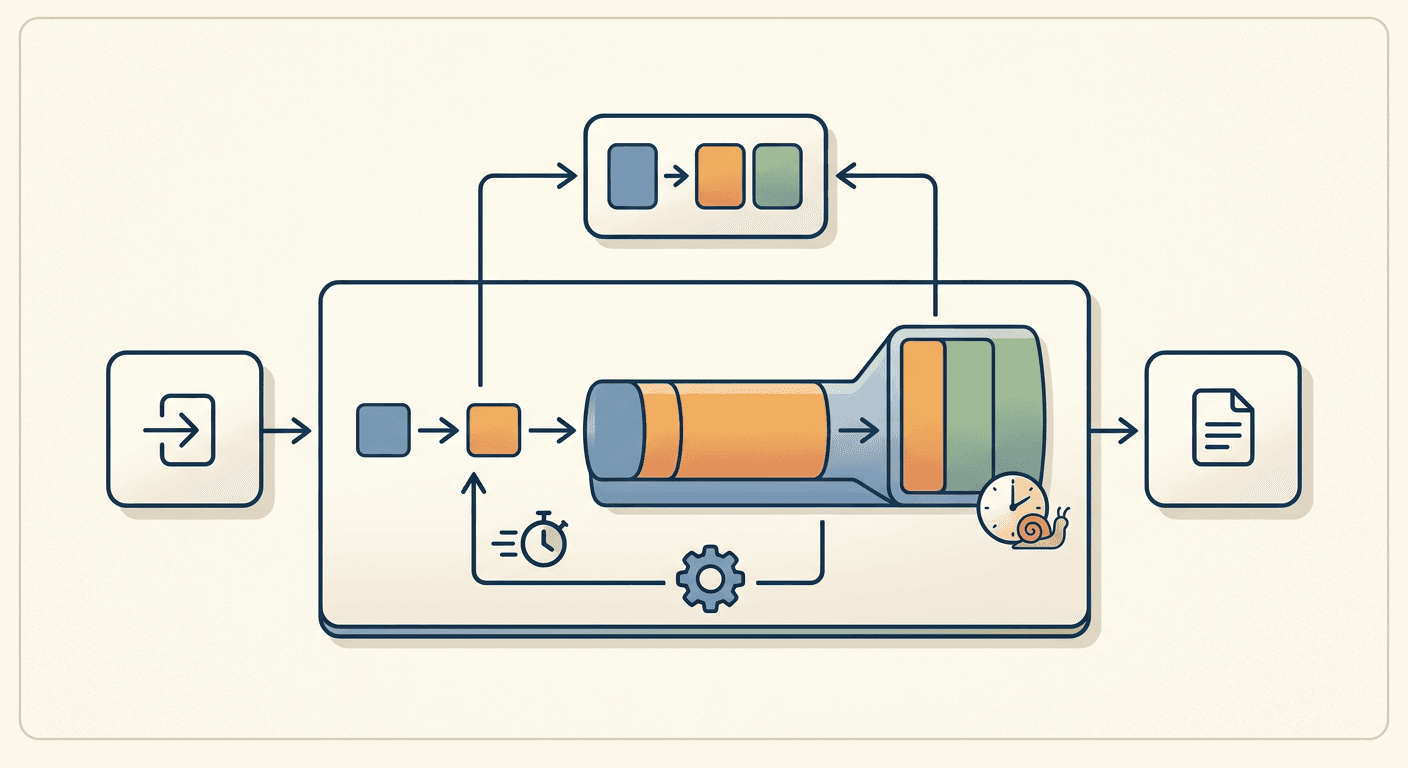
Your first few hundred tokens come back fast. By token 8,000 the same model on the same GPU is noticeably slower, and the bill is climbing in a way that doesn't feel linear with the work. Nothing about the model changed. What changed is a data structure that's been quietly growing in GPU memory the whole time: the KV cache.
The slowdown isn't the model "thinking harder" about a long prompt. It's bytes. Every token you generate forces the GPU to re-read a cache that got bigger with the previous token, and moving those bytes — not doing the math — is what caps your tokens per second.
The work you'd otherwise repeat
Transformers generate text autoregressively: one token at a time, each new token attending to every token before it. Attention needs a Key (K) and Value (V) vector for each previous position. Computed naively, every decode step would re-run the K and V projections for the entire history — token 8,000 would recompute the keys and values for tokens 1 through 7,999, throw them away, then do it again for token 8,001. That's quadratic work for something that never changes: the K and V for token 500 are identical no matter how long the sequence gets.
Enter the cache
So you keep them. The KV cache stores the K and V vectors for every token already processed, at every layer, for every attention head. A new token computes only its own K and V, appends them, and attends against everything already in the cache. Per-step attention goes from "recompute over all n tokens" to "compute one, read n." That trade is why generation is practical at all.
The catch is in that word read. You've turned a compute problem into a memory problem, and memory is where it bites.
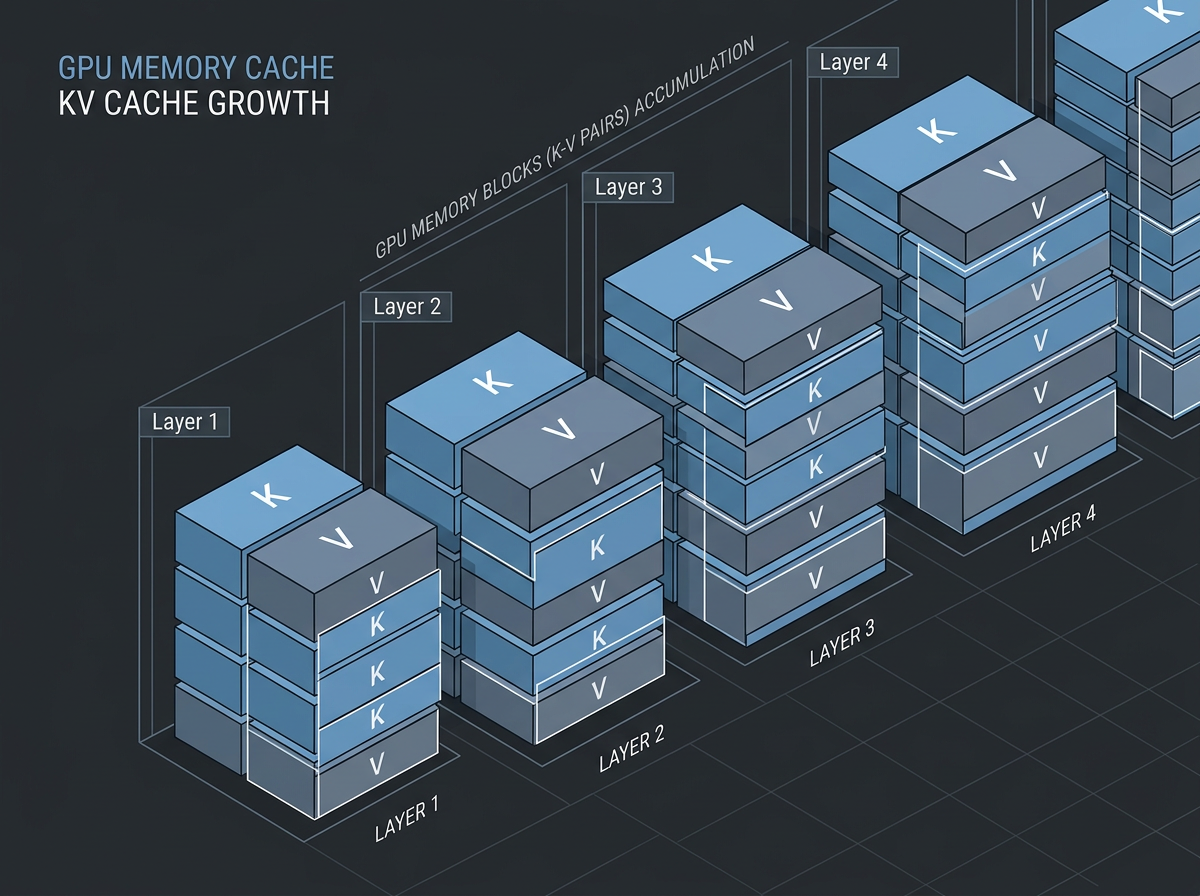
It grows, term by term
Here's the whole size story in one line:
KV cache bytes = 2 × num_layers × num_kv_heads × head_dim × seq_len × batch_size × bytes_per_element
Walk the terms:
- 2 — you store both K and V.
- num_layers — every transformer layer keeps its own cache.
- num_kv_heads — one entry per KV head; this is the term GQA and MLA attack (more below).
- head_dim — the width of each head's vector.
- seq_len — total tokens in context. This is the one that runs away.
- batch_size — concurrent sequences. The cache is per-request.
- bytes_per_element — 2 for FP16/BF16, 1 for FP8.
Two of these you control at inference time, and both are linear: double the context, double the cache; double the concurrent users, double the cache.
What that costs in practice
Numbers make it real.
| Model | Precision | Context | KV cache |
|---|---|---|---|
| Llama-2-7B | FP16 | per token | ~0.5 MB |
| Llama-2-7B | FP16 | ~28k tokens | ~14 GB |
| Llama 3.1 70B | BF16 | 128K, 1 user | ~42.9 GB |
For Llama-2-7B, ~14 GB of cache is roughly the size of the model's own FP16 weights. For Llama 3.1 70B at full 128K context, a single sequence's cache is ~43 GB — and that's before you serve a second user. The pattern: for short prompts, weights dominate memory; for long contexts, the cache dominates, and it's what decides whether the workload fits in VRAM and how fast it runs.
Why a bigger cache means slower tokens
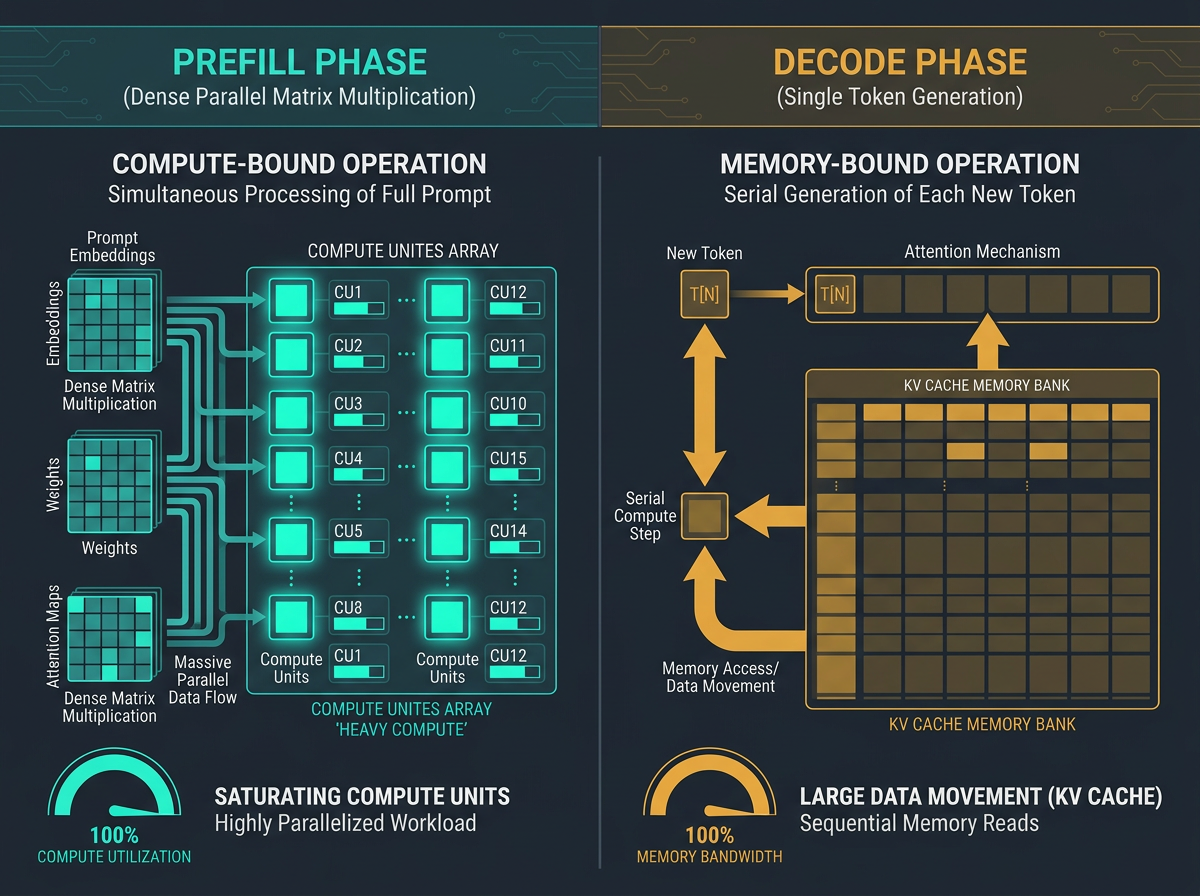
This is the part the title promises, and it comes down to the two phases of inference behaving completely differently.
Prefill — processing your prompt — is compute-bound. The whole prompt goes through in parallel as large matrix–matrix multiplications that saturate the GPU's FLOPs. Cost scales roughly quadratically with prompt length, but the hardware is busy doing math, which is what it's good at.
Decode — generating one token at a time — is memory-bandwidth-bound. Each step does very little math (matrix–vector work for a single new token) but has to stream the model weights and read the entire KV cache out of memory. The GPU isn't limited by how fast it can multiply. It's limited by how fast it can move bytes.
Put those together and the slowdown is mechanical. Every generated token re-reads the whole cache. The cache got bigger when you generated the previous token. More context → more bytes moved per step → fewer tokens per second. The model isn't working harder. It's waiting on memory.
The second tax: concurrency
Bandwidth caps single-stream speed. Capacity caps how many streams you can run at once. The cache shares VRAM with the weights, so every gigabyte of cache is a gigabyte you can't spend on batching more users or allowing longer contexts. That's why a server comfortable with 50 short-prompt users can choke on 10 long-context ones — same model, the cache just ate the headroom.
How people fight the cache
Every serious optimization targets a specific term in that formula, or the bandwidth it implies.
| Technique | What it attacks | Effect |
|---|---|---|
| Grouped-Query Attention (GQA) | num_kv_heads | Query heads share fewer KV heads (e.g. 32 → 8) for a ~4× smaller cache with negligible quality loss. Standard across all Llama 3 sizes. |
| Multi-head Latent Attention (MLA) | num_kv_heads / head_dim | Stores a small latent vector per token and reconstructs K/V on the fly. ~10× smaller cache; used in DeepSeek-V3. |
| PagedAttention (vLLM) | wasted / fragmented memory | Manages the cache in fixed-size blocks like OS paging. Cuts waste from 60–80% down to under 4%, for 2–4× throughput at the same latency. |
| Prefix caching | recompute of shared prefixes | Reuses the KV blocks of an identical prompt prefix across requests. Big win for system-prompt-heavy and agentic workloads. |
| KV quantization / offload | bytes_per_element / location | FP8 or INT4 cache, or spilling to CPU memory — trade precision or bandwidth for capacity. |
GQA and MLA shrink the cache at the architecture level, so you inherit them by picking the right model. PagedAttention and prefix caching are properties of your serving stack — vLLM and SGLang hand them to you. Quantization and offload are the knobs you turn when you're out of VRAM and willing to trade.
The mental model to keep
Context length is a memory-bandwidth tax, and you pay it on every single generated token. That reframes a few decisions. Trimming dead context isn't only about token cost — it directly buys decode speed. Reusing a fixed system-prompt prefix is worth engineering around. And when you pick a serving stack, you're really choosing how well it manages this one cache. The model's quality lives in the weights; your latency lives in the cache.
References
- Pierre Lienhart — LLM Inference Series: 3. KV caching explained
- Spheron — KV Cache Optimization Guide
- Towards Data Science — Prefill Is Compute-Bound. Decode Is Memory-Bound.
- Kwon et al. — Efficient Memory Management for LLM Serving with PagedAttention (vLLM), arXiv:2309.06180
- DeepSeek-AI — DeepSeek-V3 Technical Report, arXiv:2412.19437
- IBM — What is grouped-query attention (GQA)?


