
An LLM only knows what it saw during training. Ask it about your company's internal wiki, yesterday's pricing change, or a specific customer's order, and it will either admit it doesn't know or — far more often — hand you a fluent, confident, wrong answer. That gap between what a model was trained on and what you actually need it to answer is the problem RAG was built to close.
Retrieval-Augmented Generation (RAG) is a technique that pulls relevant information from an external knowledge source at query time and feeds it to an LLM as context, so the answer is grounded in retrieved evidence rather than the model's frozen training data alone.
Throughout this article I'll use one running example to keep things concrete: a support chatbot that answers questions from your product documentation. Everything RAG does is in service of getting the right paragraph of your docs in front of the model at the right moment.
Why does RAG exist?
Two hard limits make a raw LLM unreliable as a knowledge tool.
The first is the training cutoff. A model is a snapshot of the data it was trained on, frozen at some date. It has never seen your private codebase, your support tickets, or anything that happened after that cutoff. The second is hallucination: when a model doesn't know something, it doesn't reliably say so. It generates the most plausible-sounding continuation, which can be completely fabricated and still read as authoritative.
You could try to fix this by retraining. But retraining or fine-tuning a model every time a document changes is slow and expensive, and it still bakes the knowledge into weights where you can't easily inspect or update it. You could also just paste everything into the prompt — but dump a few thousand pages of docs into context and you hit token limits, latency, and cost ceilings fast.
RAG takes a different bet: don't put the knowledge in the model, put it next to the model. Retrieve only the handful of passages that are actually relevant to the question, and inject those at answer time. The result is more current, more verifiable, and — because you can show which sources the answer came from — citable.
Where RAG came from
The term and the recipe both come from a 2020 paper, "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," by Patrick Lewis and colleagues at Facebook AI Research (now Meta AI), University College London, and New York University. It was first posted to arXiv on May 22, 2020, and presented at NeurIPS 2020.
The idea was to pair a pre-trained seq2seq model — its "parametric memory," the knowledge stored in weights — with a dense vector index of Wikipedia that a neural retriever could search on demand, the "non-parametric memory." Per the abstract, the approach set the state of the art on three open-domain QA tasks and produced "more specific, diverse and factual language" than a parametric-only baseline. The architecture has evolved a lot since, but the core move — let the model look things up instead of memorizing everything — is exactly what every RAG system still does today.
How does RAG work?
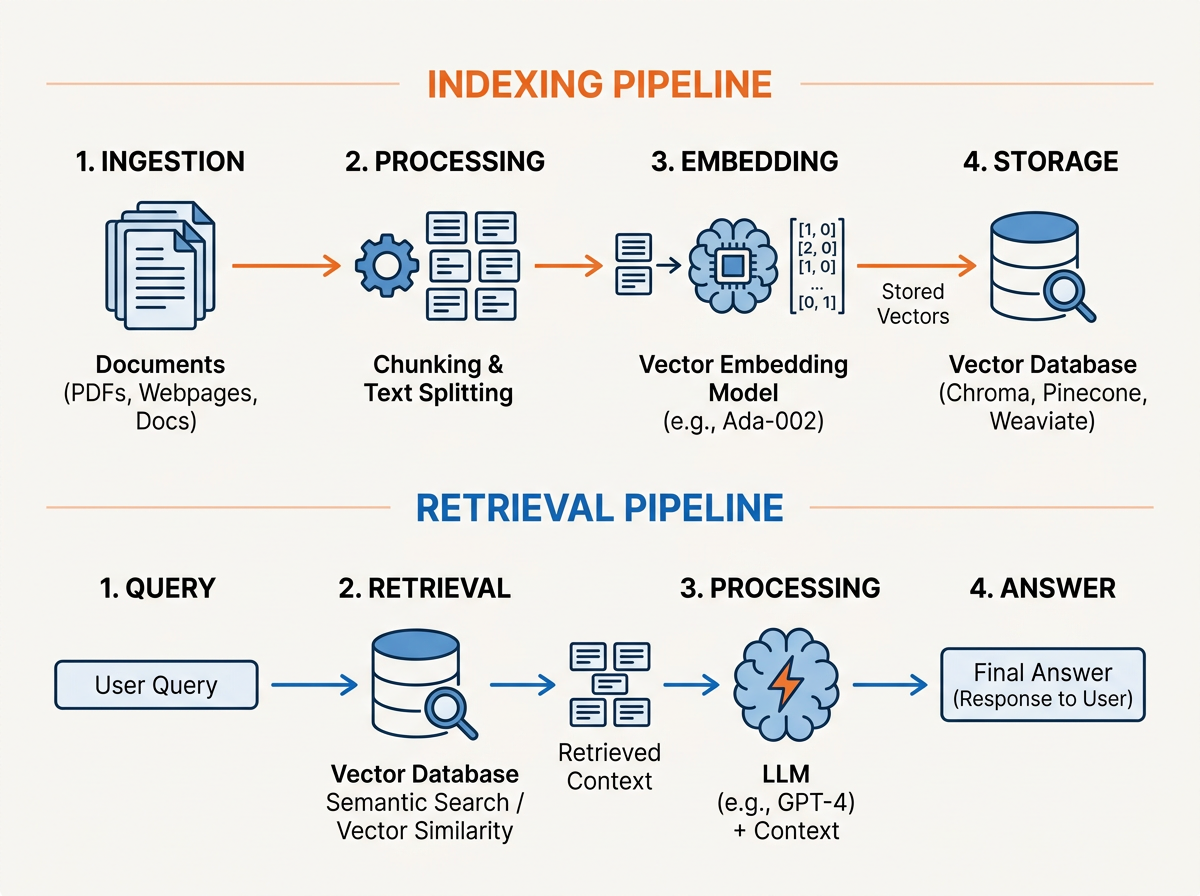
It helps to think of RAG as two separate pipelines that run at different times.
Indexing (offline). This is the ingestion step you run ahead of time, whenever your knowledge source changes:
- Load the source documents — docs, PDFs, wiki pages, support tickets, whatever holds the answers.
- Chunk them into smaller passages, usually with a bit of overlap so a thought isn't sliced in half at a boundary.
- Embed each chunk — convert the text into a numeric vector that captures its meaning, not its exact words.
- Store those vectors in a vector database built for fast similarity search.
Retrieval and generation (runtime). This runs on every user query:
- Embed the query with the same embedding model you used for the chunks.
- Search the vector database for the top-K chunks whose vectors are closest to the query's (by cosine similarity or dot product).
- Augment the prompt by stuffing those retrieved chunks, plus the original question, into the model's context.
- Generate the answer, grounded in that context — ideally with citations pointing back to the source passages.
The whole runtime path in one line: Query → embed → similarity search → top-K chunks → LLM + context → grounded answer.
For the support bot, that means a user asks "How do I reset my API key?", the system finds the three doc passages about API key management, and the model writes an answer using those passages instead of guessing from training data it may never have seen.
The building blocks worth knowing
A few terms come up constantly once you start reading about RAG. Quick definitions, in plain language:
- Embeddings — vectors that represent meaning. Two pieces of text about the same topic land near each other in vector space even if they share no words.
- Vector database — storage built to hold millions of embeddings and find the nearest ones to a query vector in milliseconds.
- Chunking — how you split documents before embedding. Chunk size and overlap have an outsized effect on retrieval quality; too big and you bury the relevant sentence, too small and you lose context.
- Top-K / retriever — how many passages you pull back per query. More candidates means better recall but a bigger, costlier prompt.
- Reranking — an optional second pass that reorders the retrieved chunks by relevance, usually with a more precise (and slower) model, before they go to the LLM.
- Hybrid search — combining semantic vector search with old-fashioned keyword search (BM25). Vectors catch meaning; keywords catch exact terms like product names and error codes that embeddings sometimes miss.
RAG vs. fine-tuning vs. long-context: when to use what
These often get framed as competitors. They solve different problems.
| Approach | Best for | Upfront cost | How you update knowledge |
|---|---|---|---|
| RAG | Facts that change or are private/external | Low — no training | Just update the index |
| Fine-tuning | Consistent style, format, or domain behavior | High — needs a labeled dataset | Retrain on new data |
| Long-context | Prototypes and one-offs; paste it all in | None | Re-paste each time |
The shorthand: reach for RAG when the answer depends on knowledge that's live, private, or too large to memorize. Reach for fine-tuning when you need the model to consistently behave a certain way — a tone, a format, a domain's conventions — on top of a stable dataset; fine-tuning changes behavior, not real-time knowledge. Use long-context when you just want to drop everything into the prompt and ship a quick prototype; it's wonderfully simple but gets expensive and unwieldy at production scale.
In practice for 2026, these aren't mutually exclusive, and the better question is rarely "which one." Production systems increasingly stack them: fine-tune a model for how it should respond, and bolt RAG on for what it should know right now.

Where RAG is heading in 2026
The basic retrieve-then-generate loop hasn't changed. The frontier is making retrieval smarter and more reliable, because that's where most RAG systems actually fail.
Agentic RAG is the headline trend. Instead of a single one-shot fetch, an agent decomposes a complex question into sub-queries, runs several retrievals, validates what it found, and synthesizes a final answer — sometimes looping back to search again when the first results fall short. It's described as a leading enterprise RAG pattern this year, and it maps naturally onto questions that no single document can answer on its own.
Retrieval quality techniques are the other half. A concrete, well-measured example is Anthropic's Contextual Retrieval, published September 19, 2024. The trick is to prepend a short, chunk-specific summary of context to each chunk before embedding it, so an isolated passage carries enough surrounding meaning to be found reliably. The reported results, measured by reduction in top-20 retrieval failure rate:
| Technique | Failure-rate reduction |
|---|---|
| Contextual Embeddings | 35% (5.7% → 3.7%) |
| Contextual Embeddings + Contextual BM25 | 49% (5.7% → 2.9%) |
| ...plus reranking | 67% (5.7% → 1.9%) |
The one-time cost to generate those contextualized chunks was about $1.02 per million document tokens using prompt caching. Reranking and hybrid search, both shown in that table, are now standard quality levers rather than exotic add-ons.
None of this replaces the loop. It just makes the retrieval step — the part that decides whether the model sees the right evidence — far less likely to whiff.
The part nobody can shortcut
RAG is the right tool when answers hinge on knowledge that's private, fast-changing, or simply too big to bake into a model. It's cheaper than retraining, it keeps your sources inspectable, and updating what the system knows is as simple as re-indexing a document.
But there's one honest caveat, and it's the whole game: RAG is only as good as what it retrieves. If the retrieval step surfaces the wrong passages, the model will faithfully ground its answer in the wrong evidence — and you've spent real engineering effort to produce a hallucination with footnotes. Get retrieval right and everything downstream tends to work. Get it wrong and no amount of prompt engineering saves you.
If you want to go further, the two natural next steps are building a minimal RAG pipeline end to end, and picking a vector database that fits your scale and latency budget. Both are easier once you can see exactly which of these steps is letting you down.
References
- Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks — arXiv:2005.11401 · NeurIPS 2020 proceedings
- Anthropic, Introducing Contextual Retrieval (Sept 19, 2024) — anthropic.com/news/contextual-retrieval
- NVIDIA, What Is Retrieval-Augmented Generation? — blogs.nvidia.com
- Oracle, Retrieval-Augmented Generation (RAG) — oracle.com


