
Full fine-tuning of a modern LLM means rewriting every weight in the model. For a 7-billion-parameter model that's gigabytes of optimizer state, a fresh multi-gigabyte checkpoint for every task you train, and enough GPU memory that you're renting datacenter hardware. LoRA breaks that cost structure. Instead of updating all the weights, you freeze them and train a tiny side module — on the order of 10,000× fewer trainable parameters and roughly 3× less GPU memory at GPT-3 175B scale, while matching full fine-tuning on quality (Hu et al., 2021). That economics shift is why LoRA is now the default parameter-efficient fine-tuning (PEFT) method.
This isn't a "clone this notebook" walkthrough. The goal is to make the mechanism legible, then give you an honest framework for when LoRA is the right call — including the 2024–2025 research showing it isn't a free lunch in every regime.
The core idea
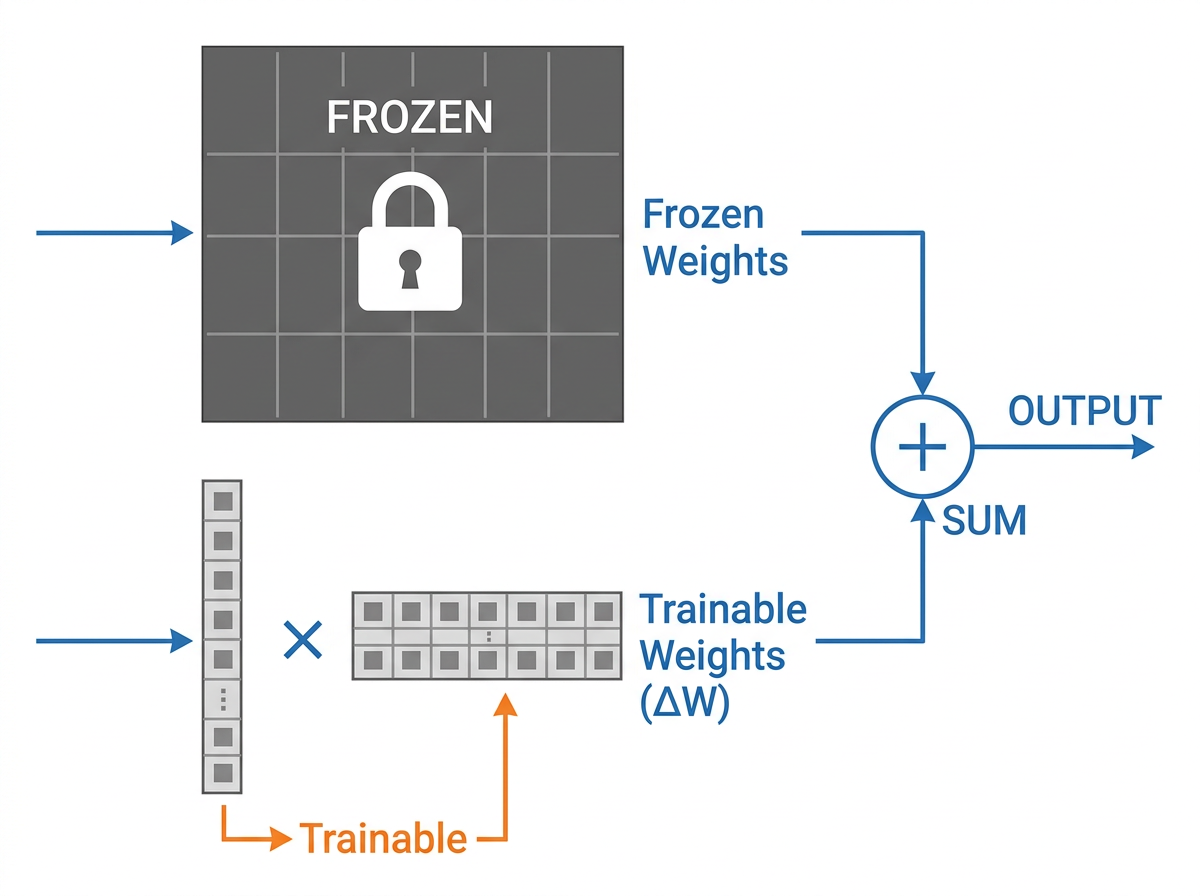
A linear layer holds a weight matrix W₀. Fine-tuning learns an update ΔW and uses W₀ + ΔW. LoRA's bet is that for a given downstream task, ΔW has low intrinsic rank — the meaningful change lives in a small subspace, even though W₀ itself is full-rank. So instead of learning the full ΔW (which is the same size as W₀), you factor it into two skinny matrices:
ΔW = B · A where A is r×k, B is d×r, and r ≪ min(d, k)
You freeze W₀ and train only A and B. The forward pass becomes:
h = W₀x + (α/r) · B·A·x
If W₀ is 4096×4096 (~16.8M parameters) and you pick rank r = 16, then A and B together hold about 131K parameters — under 1% of the original layer. A starts from a random Gaussian, B starts at zero, so ΔW is zero at step one and training begins exactly where the pretrained model left off.
One deployment win falls out of the math: at inference you can fold B·A back into W₀. The merged matrix has the same shape as the original, so there's no added latency — unlike adapter-layer methods that bolt extra modules into the forward pass.
The knobs that actually matter
Four settings carry most of the weight:
- Rank
r— the size of the bottleneck. Biggerrmeans more capacity and more parameters. Common values run 8–64; large supervised datasets can need 256 or more. - Alpha (
α) — a scaling factor. The update is scaled byα/r, soαcontrols how strongly the adapter pushes on the base model. A frequent default isα = 2r. - Target modules — which layers get adapters. The early instinct was "just the attention query/value projections." Don't. Recent analysis is blunt: "attention-only LoRA significantly underperforms MLP-only LoRA" (Thinking Machines, 2025). Apply LoRA to all linear layers, MLP included.
- Dropout — light regularization on the adapter path, useful on smaller datasets.
QLoRA: fine-tuning a 65B model on one GPU
LoRA shrinks the trainable footprint, but you still hold the full base model in memory to run the forward pass. QLoRA attacks that too: quantize the frozen base to 4-bit and backpropagate through it into the LoRA adapters (Dettmers et al., 2023). That's enough savings to fine-tune a 65B model on a single 48 GB GPU while preserving 16-bit fine-tuning task performance.
Three pieces make it work:
- 4-bit NormalFloat (NF4) — a data type that's information-theoretically optimal for the normally-distributed weights you find in a trained network.
- Double quantization — quantize the quantization constants themselves, squeezing out more memory.
- Paged optimizers — use NVIDIA unified memory to absorb the memory spikes that would otherwise OOM the run.
The headline result: the Guanaco models hit 99.3% of ChatGPT's level on the Vicuna benchmark after about 24 hours of fine-tuning on a single GPU.
The variant landscape
The names multiply fast. Here's the short version so you can navigate them.
| Method | One-line idea | Use when |
|---|---|---|
| LoRA | Low-rank update B·A on frozen weights |
The default starting point |
| QLoRA | LoRA on a 4-bit quantized base | You're memory-bound (consumer GPU, large model) |
| DoRA | Splits the update into magnitude + direction | Low ranks, where plain LoRA underperforms (non-quantized linear layers only) |
| LoRA+ | Different learning rates for A vs B |
Squeezing more efficiency out of large-model training |
| rsLoRA | Rank-stabilized scaling (α/√r instead of α/r) |
Training at higher ranks without instability |
Hugging Face PEFT is the standard library that implements all of these and keeps adding more — recent release cycles bundled in roughly nine new methods at once. For most people, LoRA and QLoRA cover the job; reach for the variants when you hit their specific failure mode.
When to use it (and when not to)
The honest version, backed by 2025 research rather than vibes.
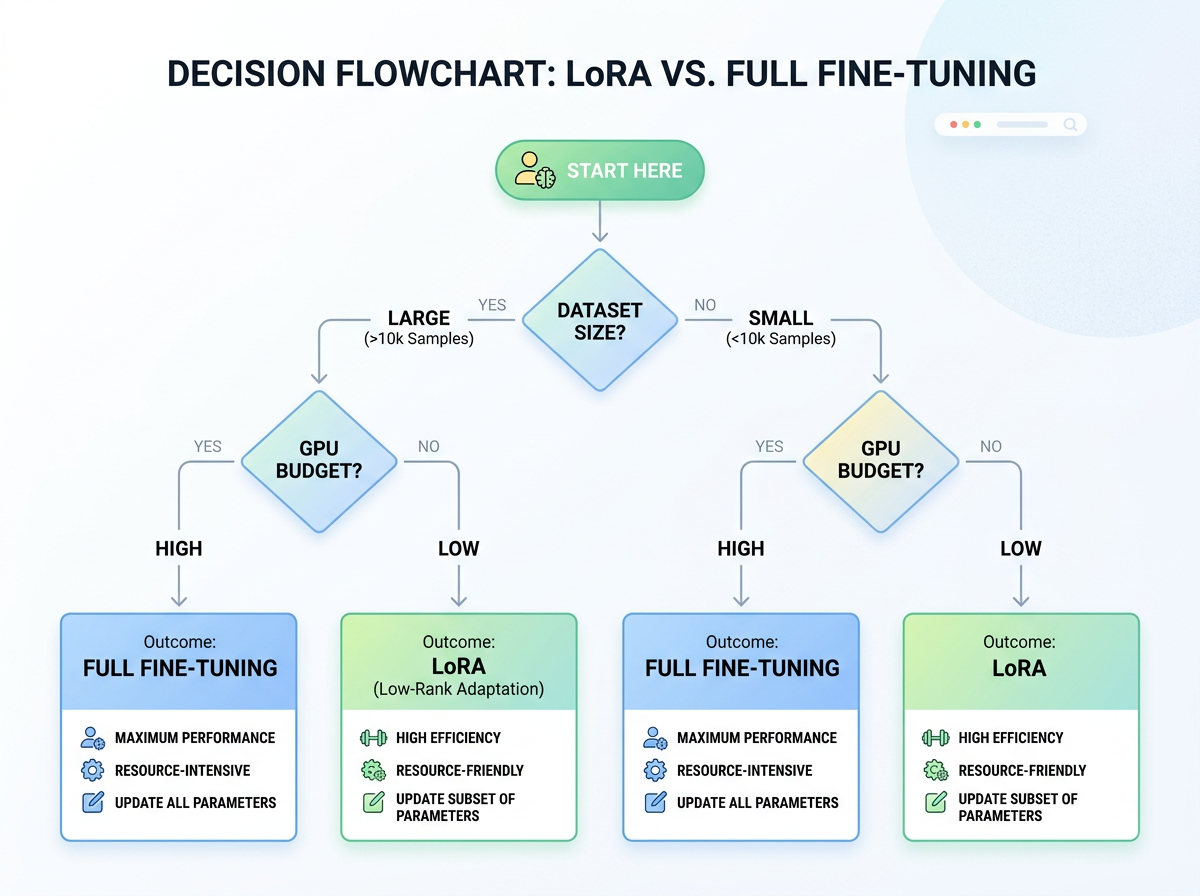
LoRA is the right call for most post-training. Instruction tuning, domain adaptation, reasoning fine-tunes, and RL on modest datasets — LoRA matches full fine-tuning here, as long as the dataset doesn't exceed the adapters' storage capacity (Thinking Machines, 2025). The mental model: LoRA holds parity while there's enough trainable capacity for the information in your data, and it degrades gracefully once you push past that — into pretraining-scale data.
A few specifics worth internalizing:
- Learning rate runs ~10× higher than full fine-tuning (closer to 15× for very short runs). This is the single most common mistake — people reuse their full-FT learning rate and conclude LoRA "doesn't work."
- Rank scales with task. Supervised instruction tuning on large datasets may want rank 256+. RL and policy-gradient methods are so sample-light that LoRA can match full FT even at rank 1.
Where full fine-tuning still wins: when the dataset is genuinely huge — beyond what the low-rank update can absorb — and when you care about the model staying a faithful model of its pretraining distribution. That last point has a name now. LoRA vs Full Fine-tuning: An Illusion of Equivalence (Shuttleworth et al., 2024) shows that even when target-task accuracy is identical, LoRA introduces new high-ranking singular vectors — "intruder dimensions" — that full fine-tuning doesn't. The practical fallout: LoRA-tuned models can become worse models of the original distribution and adapt less robustly across a sequence of tasks. Higher ranks shrink the effect. So if you're chaining several fine-tunes on top of each other, weigh that.
The serving superpower
Here's the part that changes deployment, not just training. Because every adapter shares the same frozen base, an extra adapter costs only about 50 MB of GPU memory. You can keep dozens of them resident on one GPU and hot-swap per request. Serving engines like vLLM hold multiple LoRA adapters in memory and select one per incoming request with negligible switch time.
That turns the multi-tenant math around. One base model, many small per-customer or per-task adapters, swapped on the fly — instead of one full fine-tuned model per tenant eating its own GPU.
A minimal config
With peft + transformers, the LoRA setup is small:
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16,
lora_alpha=32, # alpha = 2r is a common default
target_modules="all-linear", # not just attention — MLP too
lora_dropout=0.05,
task_type="CAUSAL_LM",
)
model = get_peft_model(base_model, config)
model.print_trainable_parameters() # sanity-check the %
Set your learning rate well above what you'd use for full fine-tuning, run print_trainable_parameters() to confirm you're training a fraction of a percent, and start at r=16 before reaching for anything fancier.
The decision, in one table
| If you... | Use |
|---|---|
| Are instruction-tuning or domain-adapting on a modest dataset | LoRA |
| Are memory-bound — big model, one consumer/single GPU | QLoRA |
| Need low rank and want more out of it | DoRA |
| Have pretraining-scale data exceeding adapter capacity | Full fine-tuning |
| Will stack several sequential fine-tunes and need robustness | Full FT, or LoRA at higher rank |
| Want to serve many tasks/tenants from shared hardware | LoRA adapters + per-request swapping |
Start with LoRA at rank 16 across all linear layers, a learning rate ~10× your full-FT default, and only escalate when you hit a wall you can name.
References
- LoRA — Hu et al., 2021 — https://arxiv.org/abs/2106.09685
- QLoRA — Dettmers et al., 2023 — https://arxiv.org/abs/2305.14314
- LoRA vs Full Fine-tuning: An Illusion of Equivalence — Shuttleworth et al., 2024 — https://arxiv.org/abs/2410.21228
- LoRA Without Regret — Thinking Machines Lab, 2025 — https://thinkingmachines.ai/blog/lora/
- LoRA+ — https://arxiv.org/abs/2402.12354
- DoRA — https://nbasyl.github.io/DoRA-project-page/
- Hugging Face PEFT — https://huggingface.co/docs/peft/en/index
- HF 4-bit / QLoRA blog — https://huggingface.co/blog/4bit-transformers-bitsandbytes
- vLLM LoRA adapters — https://docs.vllm.ai/en/latest/features/lora/

