
Generating text from a large language model is slow for a reason that has nothing to do with how smart the model is. Every new token requires a full forward pass over the entire network, one token at a time, and each of those passes is bottlenecked by memory bandwidth, not compute. The GPU spends most of its time streaming billions of weights out of memory; the actual matrix math finishes long before the next batch of weights has arrived. The arithmetic units sit mostly idle.
That idle time is the loophole. A forward pass that scores one token and a forward pass that scores five tokens cost almost the same wall-clock time, because both are dominated by loading weights, not by the math. Speculative decoding is the trick that turns that fact into a 2-3x speedup without changing a single output token.
Draft, then verify
The idea is a guess-and-check loop between two models.
A small, fast draft model proposes the next K tokens. It runs autoregressively like any model, but it's tiny, so generating a short guess is cheap. The large target model then takes all K drafted tokens and verifies them in a single forward pass, scoring every position in parallel. It accepts the longest correct prefix. If it accepts h of the K tokens, it also gets the (h+1)-th token for free out of that same verification pass, because the pass already computed the distribution at that position. Then the loop repeats.
The payoff: you spend one expensive forward pass to advance potentially several tokens instead of one. The closer the draft tracks the target, the more tokens clear per pass.
If this sounds like speculative execution in a CPU pipeline, that's exactly the borrowed intuition — compute ahead on a prediction, keep the work if the prediction held, discard it if it didn't. The name comes from the same place.
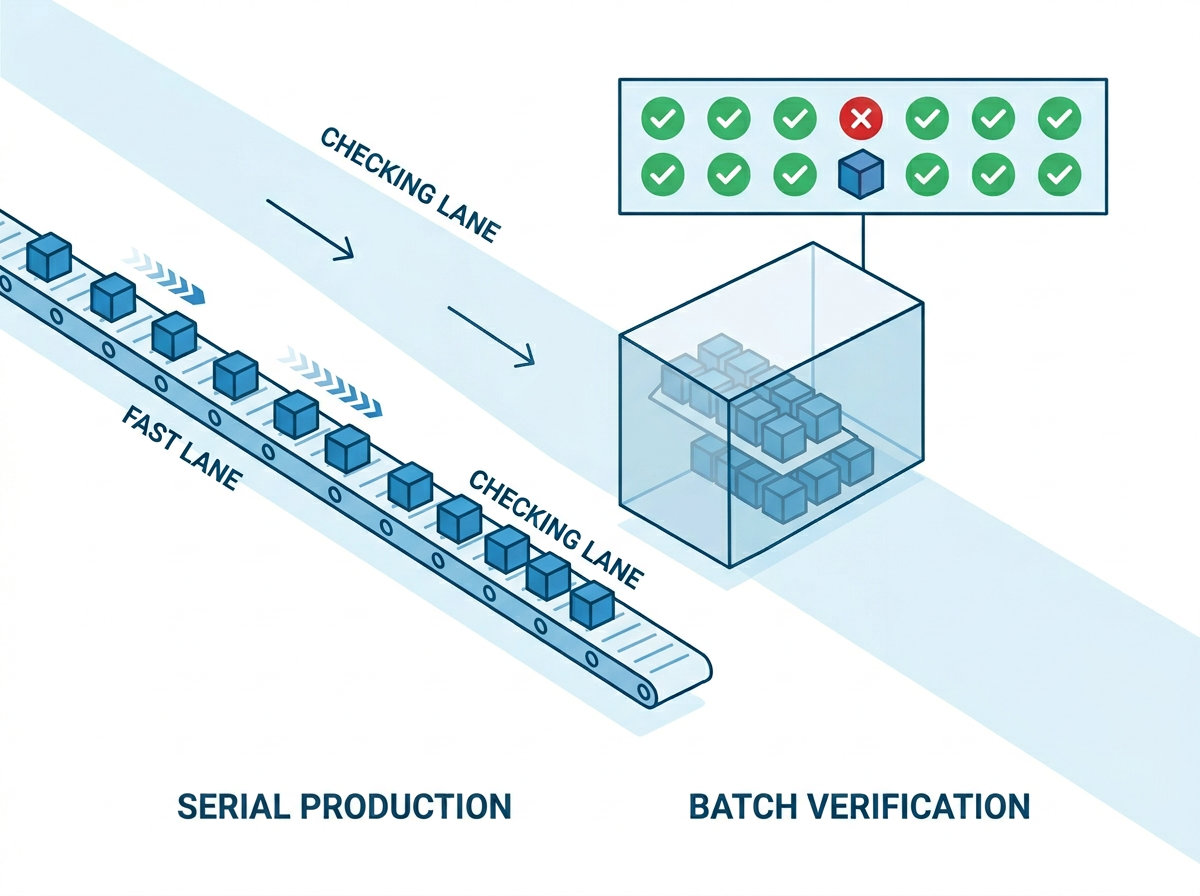
Why the output is identical
Here's the part that trips people up: speculative decoding does not approximate the big model. It produces the exact same output distribution as plain autoregressive sampling from the target. It is a speed optimization, not a quality tradeoff, and the target model is never retrained or modified.
The mechanism is a modified rejection sampling scheme. Each drafted token is accepted with a probability that depends on the ratio of the target's probability to the draft's probability for that token. When a token is rejected, it's resampled from an adjusted residual distribution. Work through the math and the accepted-plus-resampled stream is provably distributed exactly as if you'd sampled from the target directly. Greedy decoding falls out as the special case where you simply check that the draft's argmax matches the target's.
One honest caveat: "lossless" is a property of the algorithm, not a guarantee about any given implementation. A 2025 paper, Batch Speculative Decoding Done Right, found that real systems — including ones from major labs — broke the guarantee by sampling the free bonus token from the draft distribution instead of the target distribution. The math is lossless; a careless implementation isn't. If correctness matters, test that your serving stack reproduces the target's outputs.
Where the draft comes from
The original method used a separate small model. Most of the gains since have come from cheaper ways to produce a draft.
| Method | How the draft is produced | Needs a separate model? |
|---|---|---|
| Separate draft model (classic) | A small standalone model from the same family (e.g. a 1B drafting for a 70B) | Yes |
| Self-speculative / layer-skipping | The target model runs a reduced version of itself (skipping layers), sharing its KV cache | No |
| Medusa | Extra lightweight decoding heads bolted onto the model predict several future tokens at once | No (adds heads) |
| EAGLE / EAGLE-3 | A small draft head autoregresses at the model's internal feature level, reusing the target's features | No (adds a head) |
| n-gram / prompt-lookup | Copies repeated spans straight from the prompt — no neural draft at all | No |
EAGLE-3 (arXiv 2503.01840, NeurIPS 2025) is the current state of the art. Instead of predicting tokens directly, earlier EAGLE drafts at the feature level; EAGLE-3 adds multi-layer feature fusion and direct token prediction, and its acceptance rate keeps climbing as you throw more training data at it. That scaling property is why it has become the default people reach for.
How much faster, really
| Setting | Reported speedup | Notes |
|---|---|---|
| Original papers (2022-2023) | 2-3x | No quality loss, no target retraining |
| EAGLE-3 (reference) | up to ~6.5x | ~4-4.5x on MT-bench / GSM8K, acceptance length ~6 tokens |
| EAGLE-3 in vLLM | ~2-2.5x typical | Real serving gains run below the reference numbers |
| gpt-oss-120b + EAGLE3, H200 (Red Hat, 2026) | ~10-21% throughput | Decode-heavy and code workloads; 3 draft tokens, ~2.07 mean acceptance length; held up to 200 concurrent requests |
The single number that drives all of this is the acceptance rate — how often the draft guesses right. That's workload-dependent. Code and math are highly predictable and draft beautifully; open-ended chat is noisier and accepts shorter runs. Your mileage will track your traffic, not the headline figure.
When it doesn't help much
Speculative decoding is fundamentally a latency optimization — it shines on single streams and small batches, exactly the regime where the GPU is memory-bound and has spare compute to burn on verification. Crank the batch size up and that free compute disappears: the GPU is already saturated doing real work for many sequences at once, so verifying speculative tokens stops being free and the gains shrink.
Batching also creates the ragged tensor problem. Different sequences in a batch accept different numbers of tokens, so the neat rectangular tensors GPUs love turn jagged, and handling that adds overhead. That's an active research area, not a solved one.
And it's not free to operate: you have to obtain or train a draft, serve it, tune K, and eat some wasted work whenever the draft guesses wrong.
Trying it
vLLM ships native support and configures it through speculative_config. A minimal EAGLE-3 setup looks like:
speculative_config = {
"method": "eagle3",
"model": "yuhuili/EAGLE3-LLaMA3.3-Instruct-70B",
"num_speculative_tokens": 3,
}
More speculative tokens isn't automatically better — past a point, deeper drafts get rejected more often and throughput drops, so 2-3 is a common sweet spot worth measuring around. If you don't want to manage a draft model at all, the ngram (prompt-lookup) method speculates by copying repeated spans from the prompt, which works surprisingly well on summarization and code-edit workloads where output echoes input.
Decision rule: small batch and latency-critical, this is close to a free win. High-throughput batched serving, measure first — the gains may be modest or gone.
The whole trick reduces to one sentence: guess ahead with a cheap model, check with the expensive one, and let a rejection-sampling step make the guessing mathematically free in quality. The only thing left for you to decide is whether your batch sizes are small enough to collect the discount.
References
- Leviathan, Kalman & Matias, Fast Inference from Transformers via Speculative Decoding (arXiv 2211.17192, ICML 2023)
- Chen et al., Accelerating Large Language Model Decoding with Speculative Sampling (arXiv 2302.01318, DeepMind)
- EAGLE-3: Scaling up Inference Acceleration via Training-Time Test (arXiv 2503.01840, NeurIPS 2025)
- Medusa: Simple LLM Inference Acceleration Framework (arXiv 2401.10774)
- Batch Speculative Decoding Done Right (arXiv 2510.22876)
- vLLM Speculative Decoding docs
- Red Hat Developer — Performance improvements with speculative decoding in vLLM for gpt-oss
- Red Hat Developer — Fly Eagle(3) fly
- BentoML LLM Inference Handbook — Speculative decoding
- Baseten — A quick introduction to speculative decoding


